

how to clean data in python split columns
Cleanup data oft involves some combination of the following:
- Converting Data Types
- Transaction with missing or NULL values
- Replacement Values
- Removing Duplicates
We do this primarily to make sure that the data is correct and that some future operations we perform on the data will work as we expect. It's in reality rarified to work with a data set that's blank from the get go under and information scientists and analysts often fetch up spending a large amount of time cleaning before making further use of the information.
Converting Data Types
When we work with Pandas operating theatre other libraries in the Python data science stack, certain operations can merely equal performed on certain data types i.e. we can't carve up by a string. IT's hence all important that to each one column is set to contain the redress data type for it's intended employ.
There are a number of data types you can use in Pandas but commonly we use integers, floats (denary numbers), string section (in Pandas they are onymous as targe data types) and datetimes. When you import data into Pandas, information technology volition make an educated guess on what the data type is but, for various reasons, we will ofttimes desire to change those data types.
If you call the dtypes dominate on our data frame you leave see the columns name calling with corresponding information types and you will take care that Order_No, Customer_ID and Product_ID are listed atomic number 3 integers.
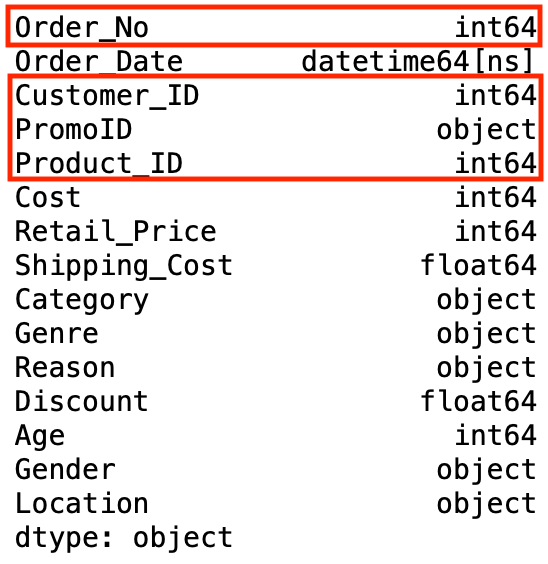
This makes sense as they're made up solely of numbers sol Pandas logically assumes that's what they are. However, in our case we demand know that these defend identifiers and therefore act names rather than to express some value. It's possible that in later these could contain letters as well as numbers so let's convert these to strings in purchase order to future substantiation our processing.
Converting Strings, Integers & Floats
To convert to integers, floats and string section we can use the astype Pandas operation and return in the data typewrite we want to change over to atomic number 3 a parameter.
df[column_name] = df[column_name].astype(data type)
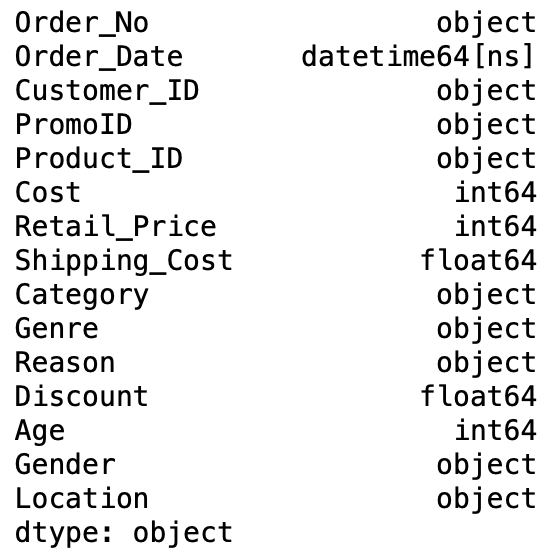
We john pass in int for whole number, float for ice-cream float and str for strings so allow's change over the Order_No, Customer_ID and Product_ID columns to strings by passing str as a parametric quantity.
df[['Order_No','Customer_ID','Product_ID']] = df[['Order_No','Customer_ID','Product_ID']].astype(str)
Converting DateTime
When we strange our orders csv we already specified that the Order_Date column should be imported as a date time. If we didn't specify this when we read the csv then Pandas would have taken the tower contains strings. You can however still win over a columns to date fourth dimension after import using the Pandas to_datetime process. The code down the stairs shows how we would do this if Order_Date had been imported as a string:
df['Order_Date'] = palladium.to_datetime(df['Order_Date'])
Handling NaNs
We will frequently see NANs in our information to represent wanting values. These can occur for various reasons: sometimes because they're simply missing in the raw data or because they are the result of not-matching rows from left operating room right outer joins. How we deal with this will depend along the particular use case and vary depending on what we are trying to achieve but Pandas comes with ii shipway to deal them retired of the box. The fillna operation allows us to fill the NaNs with a value we define and hind end be applied to a full-length data bod or a subset of columns.
In our data frame, the Rebate column contains NaNs because some of the orders did not have a discount applied and therefore those orders did not look in the original promotions data source. This resulted in NaNs when the two data sources were married through a left-of-center outward join.
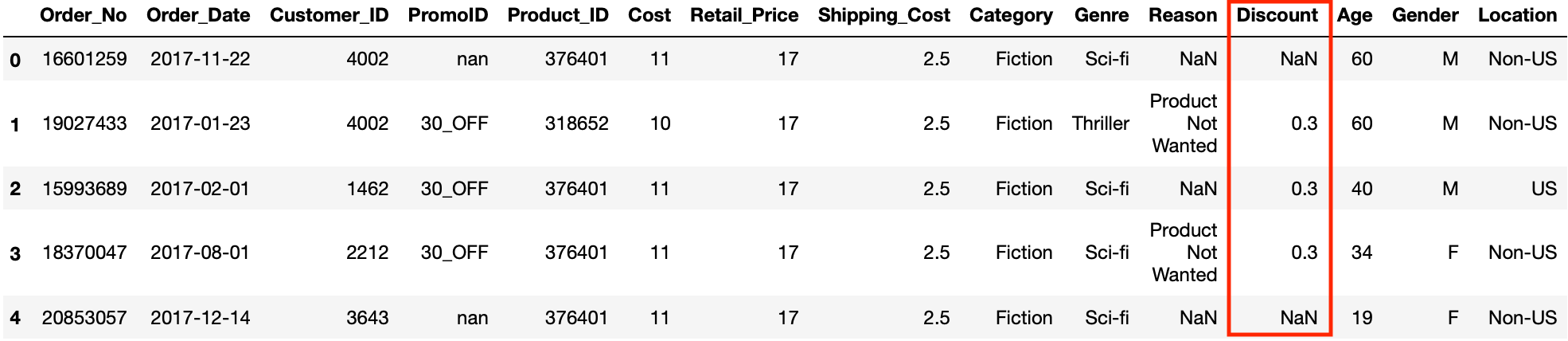
Have's fill the NaNs in this column with zeros.
df['Ignore'].fillna(0,inplace=True)
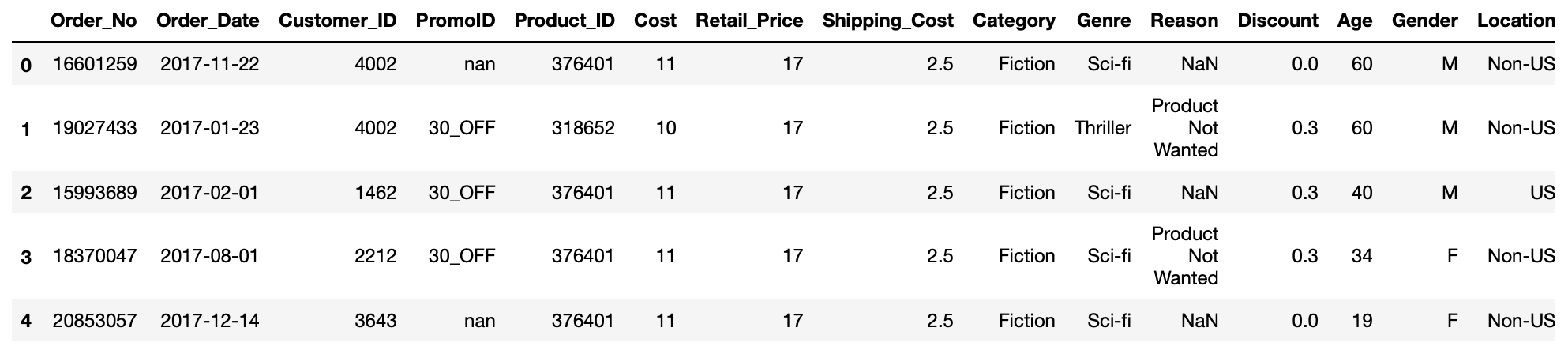
This will enable any calculations or aggregations we do with the Discount value to perform correctly as often operations involving NaNs just solution in other NaNs. Once again here, we execute the operation directly on the data frame aside victimization the inplace=True parameter.
In gain to fillna, Pandas also has the dropna operation for when the presence of NaNs indicates a row that is not needed. This operation plainly drops some rows that contain NaNs and give the axe be applied like this:
df.dropna(inplace=True)
We can also usance it to drop any columns with NaNs by exploitation the axis=1 parameter.
df.dropna(inplace=True, axis=1)
Replacing Values
The fillna operation can be thought of as a special case of the Pandas Replace operation. The Replace operation simply replaces any value in your data frame that you specify with another value that you define.
In the PromoID column we can see that close to of the values are "nan" (which is a string rather than a genuine Nan River).
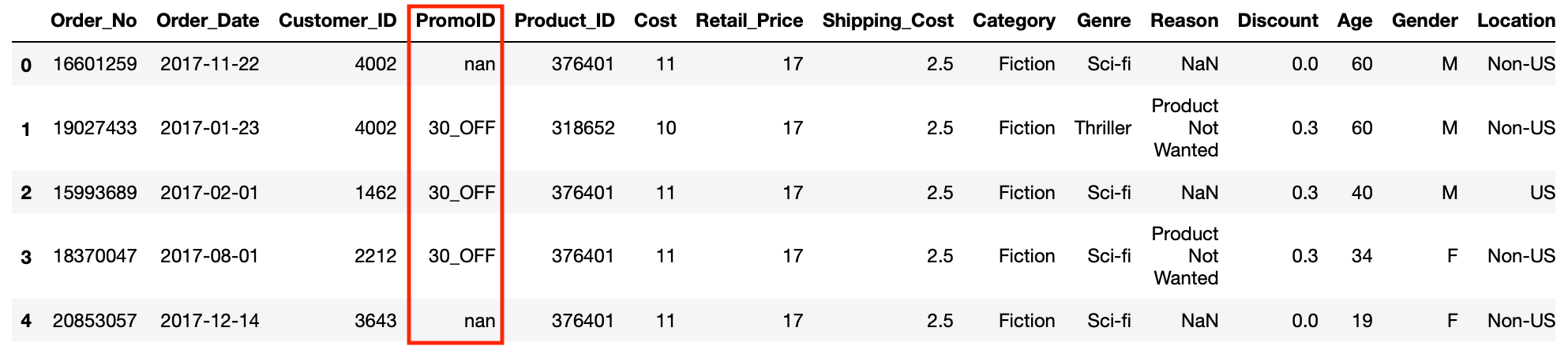
The reason we get into't get a genuine ID in on that point is because that fiat was non ordered every bit part of a promo so let's use the replace operation to replace "Nan" with the string "Full Price".
df['PromoID'].replace(to_replace='nan',appreciate='Full Price',inplace=True)
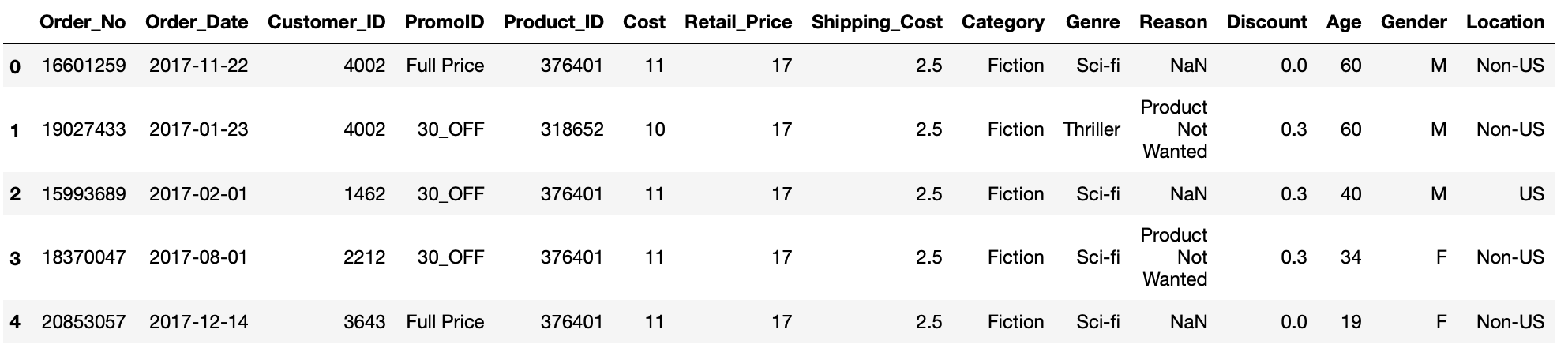
This wish enable us to differentiate our data supported on whether a intersection was organized as part of a promotional material or at full price. Once again, we perform the operation directly on the DataFrame as we Don't want to keep the original values.
Removing Duplicates
In conclusion we are going to remove any replicate rows in our data build. Extra rows can grounds double counting and misrepresentation of the values in our data. To solve this Pandas provides us with the drop_duplicates operation. Every row in our information frame should be unusual sol we can perform the operation finished the whole information inning like this:
df.drop_duplicates(inplace=True)
A Ultimate Note along Cleaning Information
A key matter to think of is that cleaning information can be a tricky undertaking and can cause issues if not finished aright. Often this requires extraordinary prior investigation of the information and some knowledge of the subject the data is describing but is something that you build an instinct for with experience. Although we haven't done IT here, sometimes cleaning individual data frames is necessary before joining them in collaboration. All information set is different and volition require a different set of steps when cleansing so it's life-or-death to spend some clip to carefully perform this part with of processing and to infer how unusual errors in your information wish touch on the task you intend to use it for.
Exercise
If you look through our data frame you will see we still take over one column that needs cleaning. As an exercise, explore the information frame, key what needs to be cleaned and apply a solution.
Solution
df['Reason'].fillna('Non Returned',inplace=True)
We requisite to fill the NaNs in the Reason column. We accept elect to fill with a "Non Returned" strand so that we can mark between returned and not-returned orders but any string that would do the same farm out is acceptable.
Next
how to clean data in python split columns
Source: https://www.analyseup.com/learn-python-for-data-science/python-pandas-cleaning-data.html
Posted by: kingseved1947.blogspot.com
0 Response to "how to clean data in python split columns"
Post a Comment